By BARBRA RODRIGUEZ
Computer-generated human head images provided by UCSC psychology professor Dominic MassaroWhen someone talks, you pick up clues about what they're saying from their facial maneuvers. Scientists are using a computerized talking image of a human head to learn about their visual language clues. Such talking heads will also allow new ways of communicating in the future.
Bill Brawner carries on phone conversations by typing words on a device called a teletypewriter hooked up to his phone. An undergrad majoring in anthropology and history at the University of California, Santa Cruz, Bill is severely hearing impaired. "If I want to talk to somebody (by phone) and I don't want to lose information, I have to use it," he says.
For face-to-face communication, he depends on the hearing he has left and his eyes. People's gestures, facial expressions, and especially their lips guide him in understanding what they're saying. Little things like arched eyebrows add a world of meaning. "I can tell if you're trying to crack a joke or being sarcastic," Bill says.
Even those clues aren't always enough, though. He hates talking with men who have bushy mustaches and people who cover their mouths with their hands. His difficulty understanding speech has made school a challenge, and he is a college sophomore at 40. "If I don't have the context right, I mess up," Bill says.
People with a hearing difficulty aren't the only ones who check out facial features while conversing. A computerized image of an animated human head has shown that we all benefit from our sight when words start flying -- even in ordinary conversations. Such computerized talking heads, as they are called, may also bring us new ways of communicating in the future.
The 3-D Computerized Talking Head:
Computerized talking heads have been in the works since the mid-70s, but their development took off this past decade with computer improvements.
Psychologist Dominic Massaro at the University of California, Santa Cruz, runs one lab that works with a talking head. He studies how people use facial information to understand speech better. To do this, Massaro and his computer assistant, Michael Cohen, developed a 3-D computerized head that produces synthetic auditory speech and synthetic visible speech.
Their 3-D head looks eerily human -- something like a flat-cheeked, evenly-toned Yul Brynner. That is, Yul Brynner minus ears and with a sliver of black for eyelashes. Nicknamed Baldy, this 3-D head has a frame under its skin similar to the chicken- wire kids use to shape plaster-of-ParisTM mountains. The head's frame consists of multiple triangles whose corners move to make the lips of Baldy pucker, his eyebrows raise, and his chin and other features change. On top of this frame, the computer can slap on a layer of skin molded to fit the head like a piece of shrink-wrap.
The end result not only looks human, but speaks in a clearly understandable, if somewhat colorless, voice when words are fed to it on a keyboard.
- A sound sample of Baldy saying "My dad taught me to drive."
- More information about AT&T's synthetic speech system
Baldy in Action:
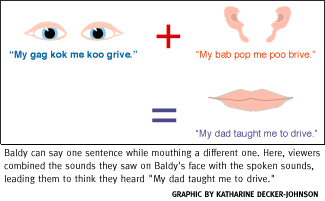
The computerized 3-D head known as Baldy can perform verbal feats beyond humans: try saying one sentence while mouthing another. Baldy can, and this skill has provided Massaro with the key to dissecting how we handle the minute details of speech.Oral languages consist of sounds joined together in ways specified by grammar rules. English speakers make words from sounds such as "mah," "moo" and the "doh" favored by the cartoon character Homer Simpson.
Massaro has found that the right combination of these sounds and facial movements made by Baldy during speech unmask the rules we use to understand spoken language. In one example, he asked people to watch Baldy say the word "ball" while mouthing "doll." Most swore Baldy actually uttered "wall." From these types of studies, Massaro concluded that visual speech and auditory speech information are both analyzed in the brain to come up with an interpretation about what was said.
The human tendency to combine both types of speech information, known as the McGurk effect, occurs even when Baldy utters and mouths very dissimilar words. Although viewers hear the parts that are completely different as verbal garbage, they try to come up with meaningful words from the mix of visible and auditory speech.
"People believe speech is auditory, and therefore visible speech shouldn't be very influential -- but, in fact, it is," says Massaro.
Our Busy Brains:
Bill Brawner and others with a hearing loss know how important sight is in interpreting what people say. Work such as Massaro's confirms the basic reliance on visible speech we all share. Psychologist Larry Rosenblum from the University of California, Riverside, who also studies our tendency to hear speech with our eyes, says, "It's as if the visual information sneaks in and affects what people's auditory perception is."Massaro's research also implies that the brain handles speech information from different sensory sources quite well. People are thought to identify other objects by zeroing in on all available details. To pick out a rhinoceros, we'd likely look for a gray-colored beast, four stumpy legs, and a cone-shaped horn for starters. Identifying an ice cream cone calls up a whole different set of images. When people listen to Baldy speak, the same appears true: their eyes help pick out the spoken words.
However, our ears still play the starring role in hearing. Silent movies were bound to lose popularity as a result, while the phone and walkie-talkie have stood the test of time. Deaf people prove humans can make do without sound, though. "The (human) system has an incredible ability to adapt to a loss of a source of information," Massaro says.
The Future of Computerized Heads:
Massaro's lab continually searches for ways to improve the way Baldy looks and talks. Already, he sports a new tongue, and a computer upgrade has added memory for more facial features. "Now we can afford to do ears," Cohen says.
They are also working to make the solemn-faced Baldy flash a semblance of a smile and show other facial emotions to learn how these influence spoken language perception. So far, the slant of your eyebrows and turn of your mouth both boost understanding the same way lip movements and other parts of visible speech do.
Massaro's and Cohen's experiments are also revealing which sounds prove most difficult to tell apart on a person's lips. Massaro hopes to use this knowledge in designing goggles to help the hearing impaired discriminate between similar looking words. The goggles, which he envisions as looking like ordinary glasses, would have a listening device that would send signals to a set of three colored lights on one of the eyepieces. A certain pattern of lights would tell if someone has just said the "mah" in "married" instead of the "bah" in "buried," for example.
Baldy may also prove useful for people learning a new language or those having difficulty picking up their native tongue. Psychologist Richard Olson at the University of Colorado, Boulder, is considering using the 3-D head to help dyslexics learn to hear, talk and read better. Dyslexia, which causes people to have trouble seeing the letters of words properly, appears to stem in part from difficulties working with speech sounds.
Dyslexics could watch Baldy talk, and see how speech sounds should be produced. Olson says the ability to take off the skin of Baldy makes the computer image especially useful, since this allows dyslexics to watch tongue movements involved in producing a sound. "In a real face, you can't always see all of the details," Olson says.
More universal applications for 3-D animated human heads await us. Keith Waters, a senior researcher at Digital Electronics Corporation in Cambridge, Massachusetts, one of the companies working on such products. He developed a computerized talking head with less precise facial movements than Baldy that may one day allow a version of video teleconferencing somewhat like that seen on the cartoon "The Jetsons." In the real-life version, a single snapshot of someone's face would be sent to the video monitor at the other end of the phone line. This image would then be updated with information on how the person's face changed during the conversation. Waters and his colleagues already have the head, known as DECface, available as a software product that can be programmed to read someone's e-mail to them using a speech synthesizer known as DECtalk. Although DECface can change expressions, no facial movements accompany the spoken mail. DECface may one day even be able to converse with a computer user as their personal assistant.